Paper reading - Interleaved Scene Graph for Interleaved Text-and-Image Generation Assessment
开发了一个交错文本和图像生成综合评估框架ISG
使用scene graph捕获文本和图像的关系,提供四个级别的评估:整体的、结构性的、块级别和特定于图像的,并引入了一个新benchmark,ISG-BENCH
作者实验认为现有模型在端到端生成文本图像交错内容时,效果不好,于是做了一个Agent来完成这个任务
motivation
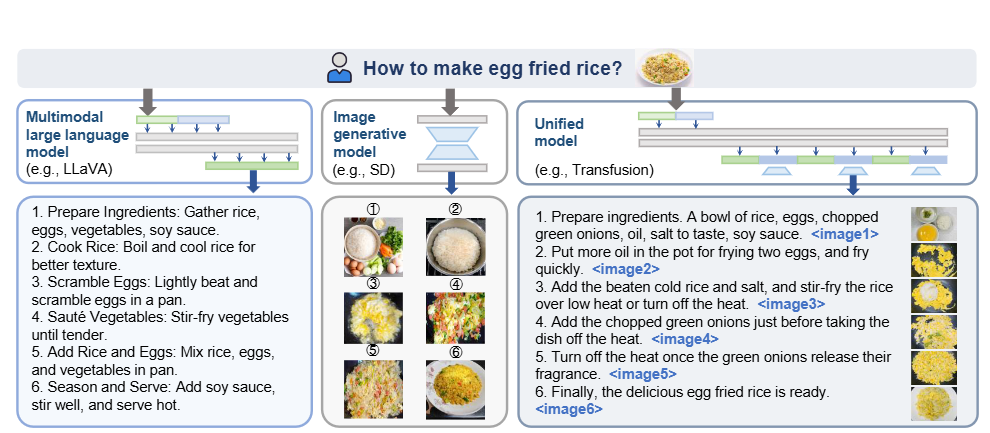
如图,现有MLLM不能直接生成交错文本和图像内容,需要将生成图像部分交给SD等外部模型再组合,带来了更大的开销与不一致性
为了专注这一任务,作者的Benchmark优先考虑视觉为中心的任务,例如风格迁移等图像输出的特定要求。
- 作者的数据集和人工标注比较有较高Pearson相似度,以此说明准确性
- 作者表示先前没什么benchmark主要以视觉为中心,以此说明新颖度
- 但有一说一,作者的表还是有点不公平的,例如它自己的sample很少(一千多),同时评估级别是自己提出的这个四级别评估
作者的表

方法
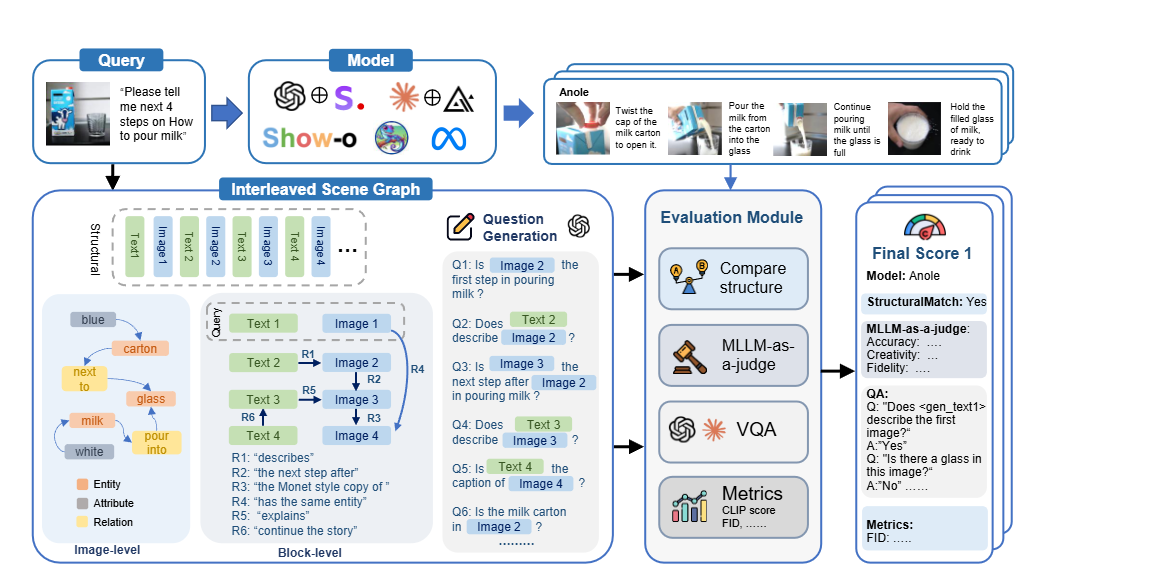
注意点: 中间看起来很复杂, 实际上是很多组prompt完成的
评估框架将query拆成scene-graph-like structure,其中图文作为节点,而它们的关系作为边
在整体,结构,块和图四级别的评估中,每个级别都会生成一些用于评估的QA对。作者的意图是,让整体和结构评估连贯性和整体质量,块和图像评估指令完成的细节
结构性:用一个LLM预估图文交替内容的结构,然后与实际生成的内容进行比较

整体:MLLM-as-a-Judge和CoT,用1-10打分配合Yes/No判断
块: 将prompt P用LLM表示成三元组 (subj, obj, rel),再用LLM生成问题,并用VQA评估

图像:从prompt 给的图像中用LLM抽出三元组关系和实体,判断query类别,根据类别不同使用不同的prompt产生判断的VQA,例如如果是"How to",则需要包含特定实体,如果是“Painting”,则需要图像的准确生成

实验结果
所有统一模型在按照说明生成交错文本和图像内容方面都存在重大缺陷。许多模型只生成 1 到 3 张图像,而有些模型根本无法生成任何图像。
整体评估结果与三个细粒度级别的评估结果之间的不一致表明,即使同时提供用户指示和正确的黄金答案,MLLM-as-a-Judge 在全面评估回答方面也存在显着局限性。具体来说,Judge MLLM 努力根据细粒度的标准评估响应,例如输出结构(包括图像数量)和提示中规定的详细文本-图像关系。此外,我们对结果的分析揭示了 MLLM-as-a-Judge 中固有的偏见,即“图像质量偏见”,即具有更高质量图像内容的回答始终获得更高的分数,尽管这些回答可能违反用户的指导要求和评判指南。这种偏见表明,即使获得了黄金答案,MLLM-as-a-Judge 仍然无法正确地对符合指定要求的交错回答进行准确评估。
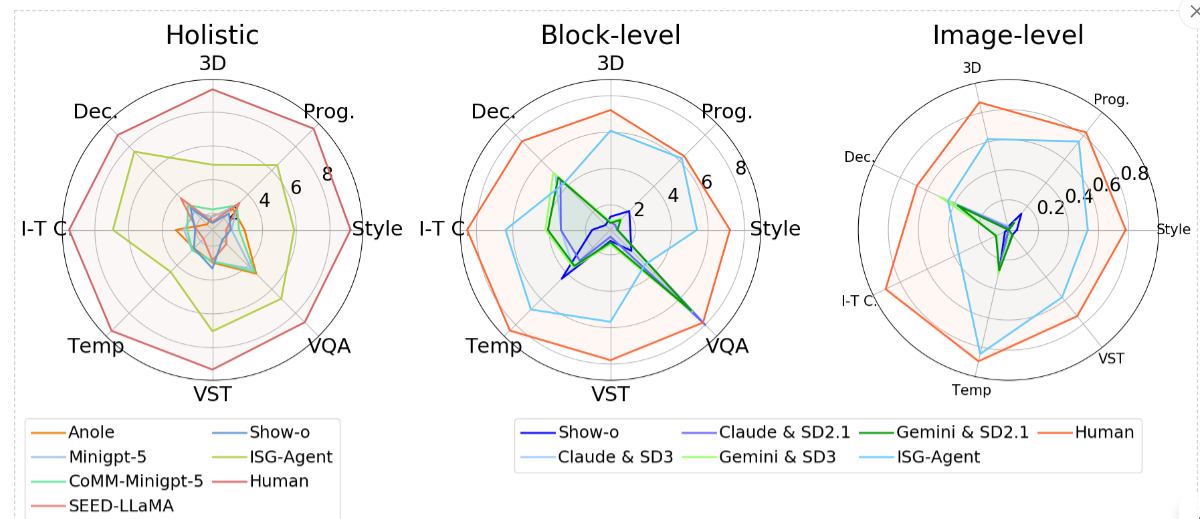
效果展示: 跑一次它这个Benchmark要60美刀

结论
- MLLM-as-a-judge存在图像质量bias
- 现有端到端MLLM生成图文内容效果不佳, 可能需要在工程性上的agent做补救